Each dataset is a SQLite database with GitHub metadata for a Jupyter organization. The data is collected using github-to-sqlite, which captures comprehensive information about repositories, issues, pull requests, users, and comments.
The rest of this page shows example analyses on the jupyter-book repository.
Showing data for last: 6 months of activity.
Download and load data¶
Use pooch to grab the latest data from GitHub releases:
db_path = pooch.retrieve(
url="https://github.com/jupyter/github-data/releases/download/latest/jupyter-book.db",
known_hash=None,
)
conn = sqlite3.connect(db_path)Downloading data from 'https://github.com/jupyter/github-data/releases/download/latest/jupyter-book.db' to file '/home/runner/.cache/pooch/344f4530266be39c90499b249209bff4-jupyter-book.db'.
SHA256 hash of downloaded file: 494c0d448259b36bb03e6459317f5f3c075e27c8bc2dce5f128159fb496ca730
Use this value as the 'known_hash' argument of 'pooch.retrieve' to ensure that the file hasn't changed if it is downloaded again in the future.
The database contains five main tables:
repos: Repository metadata (stars, forks, language, description)
issues: Issues and PRs (title, body, state, author, reactions, comment count)
users: Everyone who opened issues or PRs (login, name, type)
labels: Labels used across issues and PRs
issue_comments: Full comment text and metadata
Load them into pandas DataFrames:
repos = pd.read_sql("SELECT * FROM repos;", conn).set_index("id")
issues = pd.read_sql("SELECT * FROM issues;", conn)
users = pd.read_sql("SELECT * FROM users;", conn).set_index("id")
labels = pd.read_sql("SELECT * FROM labels;", conn)
comments = pd.read_sql("SELECT * FROM issue_comments;", conn)
# Filter to last 6 months
six_months_ago = datetime.now(timezone.utc) - timedelta(days=180)
issues['created_at'] = pd.to_datetime(issues['created_at'])
issues = issues[issues['created_at'] >= six_months_ago]
print(f"{len(repos)} repos, {len(issues)} issues+PRs, {len(users)} users, {len(comments)} comments")31 repos, 873 issues+PRs, 1427 users, 18938 comments
Repository analysis¶
Which repositories are most popular?¶
Note: Repository metadata (stars, open issue counts) reflects current GitHub totals, not filtered to 6 months.
top_repos = repos[['name', 'stargazers_count', 'open_issues_count']].sort_values(
'stargazers_count', ascending=False
).head(10)
top_reposWhich repositories have the most issue activity in the last 6 months?¶
# Count total issues (open + closed) per repository from last 6 months
issue_counts = issues.groupby('repo').size().sort_values(ascending=False).head(10)
# Get repo names
repo_names = repos.loc[issue_counts.index, 'name']
# Create bar plot
fig, ax = plt.subplots(figsize=(10, 6))
ax.barh(range(len(issue_counts)), issue_counts.values, color='steelblue')
ax.set_yticks(range(len(issue_counts)))
ax.set_yticklabels(repo_names)
ax.set_xlabel('Issues + PRs (last 6 months)')
ax.set_title('Top 10 Repositories by Recent Activity')
ax.invert_yaxis()
plt.tight_layout()
plt.show()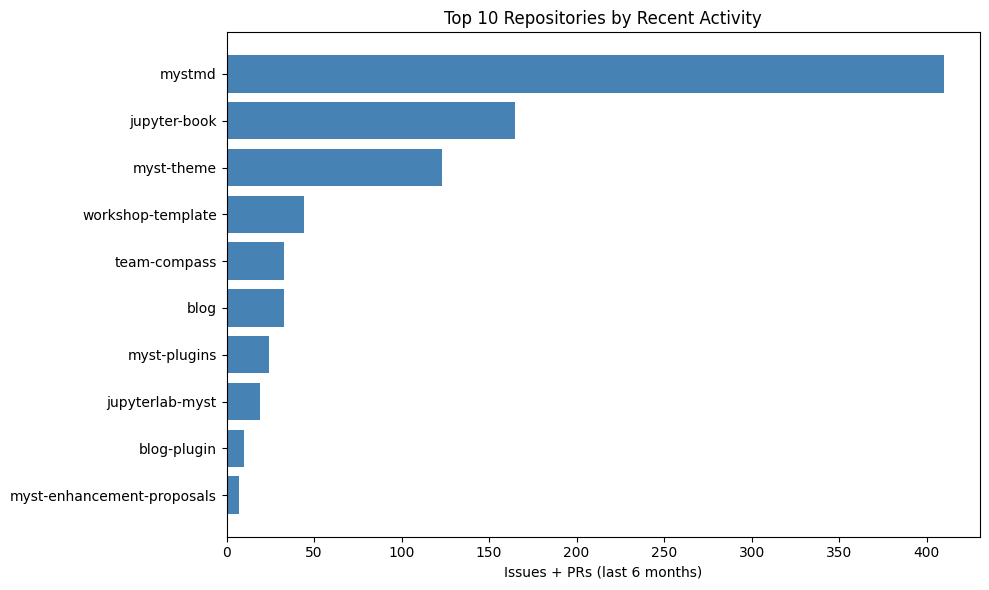
What labels are used across repositories?¶
top_labels = labels[['name', 'color', 'description']].head(10)
top_labelsIssue analysis¶
# Separate issues from PRs
issue_only = issues[issues['type'] == 'issue']
prs = issues[issues['type'] == 'pull'].copy()
print(f"{len(issue_only)} issues, {len(prs)} PRs")432 issues, 441 PRs
Who opens the most issues?¶
top_issue_authors = issue_only['user'].value_counts().head(10)
# Join with user info
issue_authors_df = pd.DataFrame({'issues_opened': top_issue_authors}).join(users[['login', 'type']])
issue_authors_dfWhich issues get the most discussion?¶
top_discussed = issue_only.nlargest(5, 'comments')[['number', 'title', 'state', 'comments']]
top_discussedWhat reactions do issues receive?¶
# Parse reactions from the reactions column
reaction_counts = {'+1': 0, 'heart': 0, 'hooray': 0, 'rocket': 0, 'eyes': 0}
for reaction_str in issues['reactions'].dropna():
try:
reactions = eval(reaction_str)
for key in reaction_counts.keys():
reaction_counts[key] += reactions.get(key, 0)
except:
pass
reactions_df = pd.DataFrame([reaction_counts], index=['Total']).T.sort_values('Total', ascending=False)
reactions_dfWhich repos have the most open issues from the last 6 months?¶
open_issues = issue_only[issue_only['state'] == 'open'].copy()
# Add repo names
open_issues = open_issues.merge(
repos[['name']], left_on='repo', right_index=True, how='left'
)
# Count by repo
issues_per_repo = open_issues.groupby('name').size().sort_values(ascending=False).head(10)
open_issues_df = pd.DataFrame({'open_issues_last_6mo': issues_per_repo})
open_issues_dfPull request analysis¶
All PR metrics below use the 6-month filtered data.
Who opens the most PRs?¶
top_pr_authors = prs['user'].value_counts().head(10)
# Join with user info
pr_authors_df = pd.DataFrame({'prs_opened_last_6mo': top_pr_authors}).join(users[['login', 'type']])
pr_authors_dfWhich PRs get the most discussion?¶
most_discussed_prs = prs.nlargest(5, 'comments')[['number', 'title', 'state', 'comments']]
most_discussed_prsWho comments on PRs the most?¶
Note: Comment data is not filtered by time - it includes all comments on PRs from the last 6 months.
# Get all PR IDs
pr_ids = set(prs['id'])
# Filter comments to only those on PRs
pr_comments = comments[comments['issue'].isin(pr_ids)]
# Count comments by user
top_pr_commenters = pr_comments['user'].value_counts().head(10)
# Join with user info
pr_commenters_df = pd.DataFrame({'pr_comments': top_pr_commenters}).join(users[['login', 'type']])
pr_commenters_dfHow long do PRs stay open?¶
prs['created'] = pd.to_datetime(prs['created_at'])
prs['closed'] = pd.to_datetime(prs['closed_at'])
prs['days_open'] = (prs['closed'] - prs['created']).dt.days
# Only look at merged PRs
merged = prs[prs['state'] == 'closed'].nlargest(5, 'days_open')
longest_open_prs = merged[['number', 'title', 'days_open']]
longest_open_prsWhich repos have the most PR activity in the last 6 months?¶
# Add repo names to PRs
prs_with_repos = prs.merge(
repos[['name']], left_on='repo', right_index=True, how='left'
)
# Count PRs per repo
prs_per_repo = prs_with_repos.groupby('name').size().sort_values(ascending=False).head(10)
pr_activity_df = pd.DataFrame({'prs_last_6mo': prs_per_repo})
pr_activity_dfWhich repos have the most PR discussion in the last 6 months?¶
# Join PR comments with repo info
pr_comment_repos = pr_comments.merge(
issues[['id', 'repo']], left_on='issue', right_on='id', how='left'
).merge(
repos[['name']], left_on='repo', right_index=True, how='left'
)
# Count PR comments by repo
comments_per_repo = pr_comment_repos.groupby('name').size().sort_values(ascending=False).head(10)
pr_discussion_df = pd.DataFrame({'pr_comments': comments_per_repo})
pr_discussion_dfAll datasets updated daily at: https://